Features of Apache Sqoop:
- Import sequential datasets from mainframe – Sqoop satisfies the growing need to move data from the mainframe to HDFS.
- Import direct to ORC files – Improves compression and lightweight indexing and improve query performance.
- Parallel data transfer – For faster performance and optimal system utilization.
- Efficient data analysis – Improve efficiency of data analysis by combining structured data and unstructured data on a schema on reading data lake.
- Fast data copies – from an external system into Hadoop.
How Sqoop Works?
The following image describes the workflow of Sqoop.
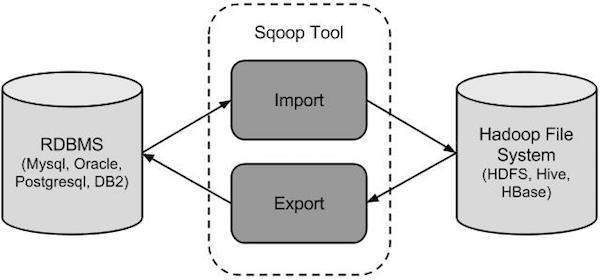
Sqoop Import
The import tool imports individual tables from RDBMS to HDFS. Each row in a table is treated as a record in HDFS. All records are stored as text data in text files or as binary data in Avro and Sequence files.
Sqoop Export
The export tool exports a set of files from HDFS back to an RDBMS. The files given as input to Sqoop contain records, which are called as rows in table. Those are read and parsed into a set of records and delimited with a user-specified delimiter.
Syntax
The following syntax is used to import data
$ sqoop import(generic-args)(import-args) $ sqoop-import(generic-args)(import-args)
The following is the syntax for the export command.
$ sqoop export(generic-args)(export-args) $ sqoop-export(generic-args)(export-args)
The following is the syntax for creating a Sqoop job.
$ sqoop job (generic-args)(job-args)[--[subtool-name](subtool-args)] $ sqoop-job (generic-args)(job-args)[--[subtool-name](subtool-args)]
Apache Flume
Flume efficiently collects, aggregate and moves a large amount of data from its origin and sending it back to HDFS. It is fault tolerant and reliable mechanism. This Hadoop Ecosystem component allows the data flow from the source into Hadoop environment. It uses a simple extensible data model that allows for the online analytic application. Using Flume, we can get the data from multiple servers immediately into hadoop. Apache Flume is a tool used to collect, aggregate and transports large amounts of streaming data like log files, events, etc., from a number of different sources to a centralized data store. Flume is a highly distributed, reliable, and configurable tool. Flume was mainly designed in order to collect streaming data (log data) from various web servers to HDFS.
Flume Features
Some of the outstanding features of Flume are as follows:
- From multiple servers, it collects the log data and ingests them into a centralized store (HDFS, HBase) efficiently.
- With the help of Flume we can collect the data from multiple servers in real-time as well as in batch mode.
- Huge volumes of event data generated by social media websites like Facebook and Twitter and various e-commerce websites such as Amazon and Flipkart can also be easily imported and analyzed in real-time.
- Flume can collect data from a large set of sources and move them to multiple destinations.
- Multi-hop flows, fan-in fan-out flows, contextual routing, etc are supported by Flume.
- Flume can be scaled horizontally.
Apache Flume Architecture
In this section of Apache Flume tutorial, we will discuss various components of Flume and how this components work-
- Event: A single data record entry transported by flume is known as Event.
- Source: Source is an active component that listens for events and writes them on one or channels. It is the main component with the help of which data enters into the Flume. It collects the data from a variety of sources, like exec, avro, JMS, spool directory, etc.
- Sink: It is that component which removes events from a channel and delivers data to the destination or next hop. There are multiple sinks available that delivers data to a wide range of destinations. Example: HDFS, HBase, logger, null, file, etc.
- Channel: It is a conduit between the Source and the Sink that queues event data as transactions. Events are ingested by the sources into the channel and drained by the sinks from the channel.
- Agent: An Agent is a Java virtual machine in which Flume runs. It consists of sources, sinks, channels and other important components through which events get transferred from one place to another.
- Client: Events are generated by the clients and are sent to one or more agents.
Advantages of Flume
Below are some important advantages of using Apache Flume:
- Data into any of the centralized stores can be stored using Apache Flume.
- Flume acts as a mediator between data producers and the centralized stores when the rate of incoming data exceeds the rate at which data can be written to the destination and provides a steady flow of data between them.
- A feature of contextual routing is also provided by Flume.
- Flume guarantees reliable message delivery as in Flume transactions are channel-based where two transactions (1 sender & 1 receiver) are maintained for each message.
- Flume is highly fault-tolerant, reliable, manageable, scalable, and customizable.



























