Apache HADOOP is a framework used to develop data processing applications which are executed in a distributed computing environment. Similar to data residing in a local file system of the personal computer system, in Hadoop, data resides in a distributed file system which is known as Hadoop Distributed File system.
The processing model is based on 'Data Locality' concept wherein the computational logic is sent to cluster nodes(server) containing data. This computational logic is nothing but a compiled version of a program written in a high-level language such as Java, data is processed, stored on Hadoop HDFS.
HADOOP is an open source software framework. Applications built using it run on large data sets distributed across clusters of commodity computers.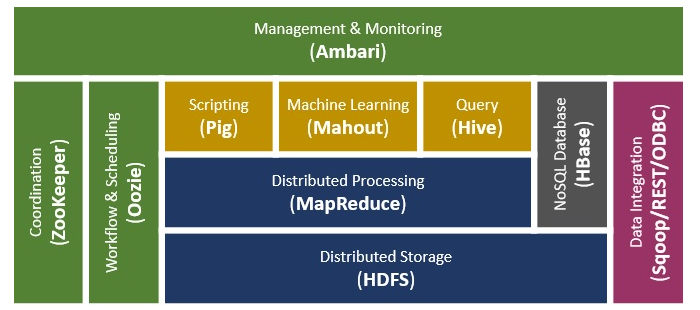
Hadoop Ecosystem Components
1. Hadoop Distributed File System
It is the most important component of the Hadoop Ecosystem. HDFS is the primary storage system for Hadoop. Hadoop distributed file system (HDFS) is a java based file system that provides scalable, fault tolerance, reliable and cost efficient data storage for Big data.
HDFS Components:
There are two major components of Hadoop HDFS- NameNode and DataNode.
2. MapReduce
Hadoop MapReduce is the core Hadoop ecosystem component which provides data processing. MapReduce is a software framework for easily writing applications that process the vast amount of structured and unstructured data stored in the Hadoop Distributed File system. It improves the speed and reliability of cluster this parallel processing.
Working of MapReduce
Hadoop Ecosystem component ‘MapReduce’ works by breaking the processing into two phases:
- Map phase
- Reduce phase
3. YARN
Hadoop YARN (Yet Another Resource Negotiator) is also one of the most important components of the Hadoop Ecosystem. YARN is called as the operating system of Hadoop as it is responsible for managing and monitoring workloads. It allows multiple data processing engines such as real-time streaming and batch processing to handle data stored on a single platform.
Main features of YARN are:
- Flexibility
- Efficiency
- Shared
4. Hive
The Hadoop ecosystem component, Apache Hive, is an open source data warehouse system for querying and analyzing large datasets stored in Hadoop files. Hive do three main functions: data summarization, query, and analysis.
Hive use language called HiveQL (HQL), which is similar to SQL. HiveQL automatically translates SQL-like queries into MapReduce jobs which will execute on Hadoop.
Main parts of Hive are:
- Metastore – It stores the metadata.
- Driver – Manage the lifecycle of a HiveQL statement.
- Query compiler – Compiles HiveQL into Directed Acyclic Graph(DAG).
- Hive server – Provide a thrift interface and JDBC/ODBC server.
5. Pig
Apache Pig is a high-level language platform for analyzing and querying huge dataset that is stored on HDFS. Pig as a component of Hadoop Ecosystem uses PigLatin language. It is very similar to SQL. It loads the data, applies the required filters and dumps the data in the required format. For Programs execution, pig requires Java runtime environment.
Features of Apache Pig:
- Extensibility
- Optimization opportunities
- Handles all kinds of data
6. HBase
Apache HBase is a Hadoop ecosystem component which is a distributed database that was designed to store structured data in tables that could have billions of row and millions of columns. HBase is scalable, distributed, and NoSQL database that is built on top of HDFS. HBase, provide real-time access to read or write data in HDFS.
Components of HBase:
- HBase Master
- RegionServer
7. HCatalog
It is a table and storage management layer for Hadoop. HCatalog supports different components available in the Hadoop ecosystem like MapReduce, Hive, and Pig to easily read and write data from the cluster. HCatalog is a key component of Hive that enables the user to store their data in any format and structure.
By default, HCatalog supports RCFile, CSV, JSON, sequenceFile and ORC file formats.
Benefits of HCatalog:
- Enables notifications of data availability.
- With the table abstraction, HCatalog frees the user from overhead of data storage.
- Provide visibility for data cleaning and archiving tools.
8. Avro
Acro is a part of Hadoop ecosystem and is a most popular Data serialization system. Avro is an open source project that provides data serialization and data exchange services for Hadoop. These services can be used together or independently. Big data can exchange programs written in different languages using Avro.Features provided by Avro:
- Rich data structures.
- Remote procedure call.
- Compact, fast, binary data format.
- Container file, to store persistent data.
9. Thrift
It is a software framework for scalable cross-language services development. Thrift is an interface definition language for RPC(Remote procedure call) communication. Hadoop does a lot of RPC calls so there is a possibility of using Hadoop Ecosystem component Apache Thrift for performance or other reasons.
10. Apache Drill
The main purpose of the Hadoop Ecosystem Component is large-scale data processing including structured and semi-structured data. It is a low latency distributed query engine that is designed to scale to several thousands of nodes and query petabytes of data. The drill is the first distributed SQL query engine that has a schema-free model.
Features of Apache Drill:
- Extensibility
- Flexibility
- Dynamic schema discovery
- Drill decentralized metadata
11. Apache Mahout
Mahout is an open source framework for creating scalable machine learning algorithm and data mining library. Once data is stored in Hadoop HDFS, mahout provides the data science tools to automatically find meaningful patterns in those big data sets.
Algorithms of Mahout are:
Clustering
Collaborative filtering
Classifications
Frequent pattern mining
12. Apache Sqoop
Sqoop imports data from external sources into related Hadoop ecosystem components like HDFS, HBase or Hive. It also exports data from Hadoop to other external sources. Sqoop works with relational databases such as Teradata, Netezza, Oracle, MySQL.
Features of Apache Sqoop:
- Import sequential datasets from mainframe
- Import direct to ORC files
- Parallel data transfer
- Efficient data analysis
- Fast data copies
13. Apache Flume
Flume efficiently collects, aggregate and moves a large amount of data from its origin and sending it back to HDFS. It is fault tolerant and reliable mechanism. This Hadoop Ecosystem component allows the data flow from the source into the Hadoop environment. It uses a simple extensible data model that allows for the online analytic application. Using Flume, we can get the data from multiple servers immediately into Hadoop.
14. Ambari
Ambari, another Hadoop ecosystem component, is a management platform for provisioning, managing, monitoring and securing Apache Hadoop cluster. Hadoop management gets simpler as Ambari provide consistent, secure platform for operational control.
Features of Ambari:
- Simplified installation, configuration, and management
- Centralized security setup
- Highly extensible and customizable
- Full visibility into cluster health
15. Zookeeper
Apache Zookeeper is a centralized service and a Hadoop Ecosystem component for maintaining configuration information, naming, providing distributed synchronization, and providing group services. Zookeeper manages and coordinates a large cluster of machines.Features of Zookeeper:
- Fast
- Ordered
Oozie combines multiple jobs sequentially into one logical unit of work. Oozie framework is fully integrated with Apache Hadoop stack, YARN as an architecture center and supports Hadoop jobs for Apache MapReduce, Pig, Hive, and Sqoop. Oozie is very much flexible as well. One can easily start, stop, suspend and rerun jobs. It is even possible to skip a specific failed node or rerun it in Oozie.
There are two basic types of Oozie jobs:
- Oozie workflow – It is to store and run workflows composed of Hadoop jobs.
- Oozie Coordinator – It runs workflow jobs based on predefined schedules and availability of data.
Features of Hadoop
- Open Source
- Distributed Processing
- Fault Tolerance
- Reliability
- High Availability
- Scalability
- Economic
- Easy to use
- Data Locality
Network Topology In Hadoop
Topology (Arrangement) of the network, affects the performance of the Hadoop cluster when the size of the Hadoop cluster grows. In addition to the performance, one also needs to care about the high availability and handling of failures. In order to achieve this Hadoop, cluster formation makes use of network topology.
Typically, network bandwidth is an important factor to consider while forming any network. However, as measuring bandwidth could be difficult, in Hadoop, the network is represented as a tree and distance between nodes of this tree (number of hops) is considered as an important factor in the formation of Hadoop cluster. Here, the distance between two nodes is equal to the sum of their distance to their closest common ancestor.
Hadoop Cluster
Hadoop cluster consists of the data center, the rack and the node which actually executes jobs. Here, data center consists of racks and rack consists of nodes. Network bandwidth available to processes varies depending upon the location of the processes.
That is, the bandwidth available becomes lesser as we go away from-
- Processes on the same node
- Different nodes on the same rack
- Nodes on different racks of the same data center
- Nodes in different data centers


























